本篇笔记包括对以下经典模型的个人总结和理解:
- Faster R-CNN
- YOLO 系列
- SSD
- Resnet
不断更新ing…
Faster R-CNN
Faster R-CNN是two-stage检测框架的代表作,在各大竞赛的排行榜上,以它为基础的变体都占据着统治地位。Faster R-CNN的网络结构图如下图:
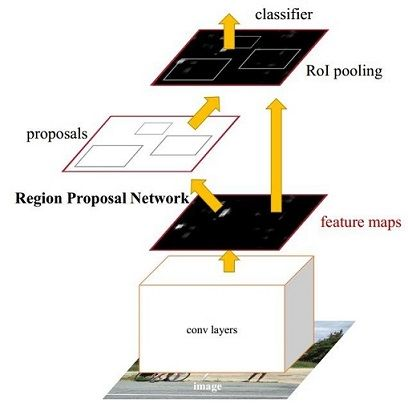
按照流程来说,Faster R-CNN的整体架构可以看下图(以VGG为例):

Faster R-CNN的检测流程是:首先使用深度卷积网络作为Backbone,从原始图像中抽取一张特征图;随后根据RPN输出的候选区域截取主干网络输出的特征图;之后通过RoI pooling得到最终的Head,并进行bounding box regression&classification;最后一个后处理过程NMS则搜索局部极大值、抑制非极大值元素。
它的几个突出贡献点如下:
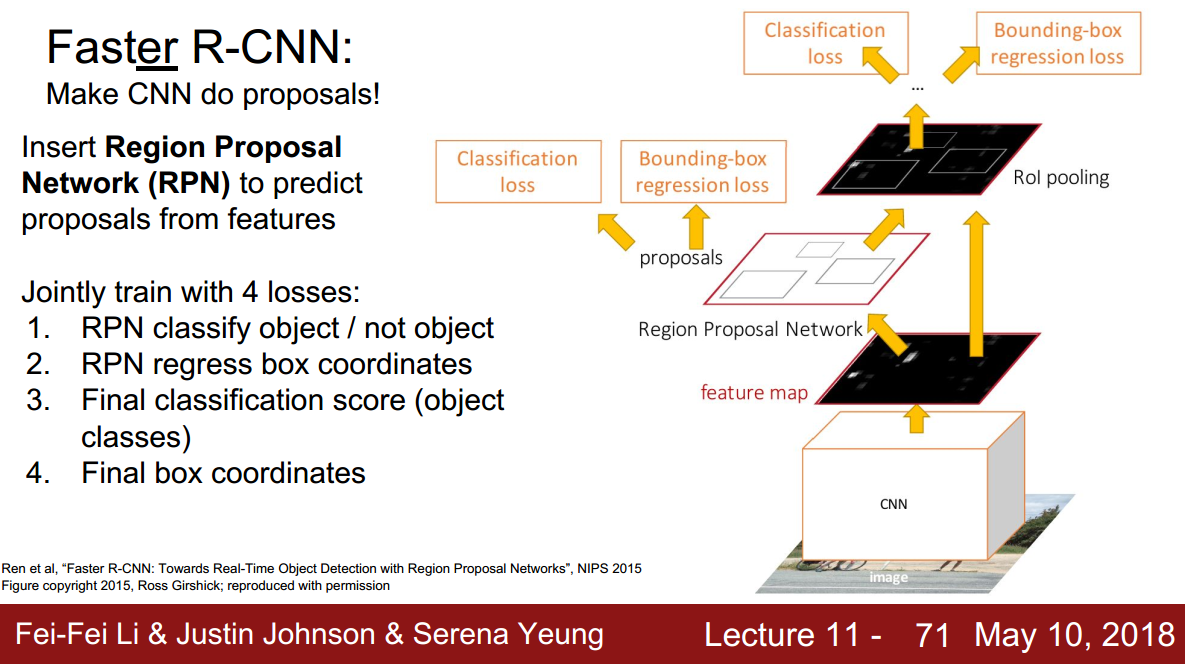
- 提出了RPN网络,用来生成region proposal;
- 在RPN中引入了anchor,通过对anchor进行二分类(background/foreground)初步筛选Proposal。Anchor即大小和尺寸固定的候选框。论文中用到的anchor有三种尺寸和三种比例,如下图所示,三种尺寸分别是小(蓝128)中(红256)大(绿512),三个比例分别是1:1,1:2,2:1。3×3的组合总共有9种anchor。

- RPN网络和后续分类/回归网络共享卷积层特征,即将region proposal和 整合到一个网络中,大大提高了生成候选区域的速度(2s -> 0.01s);
- 使用ROI pooling将不同的proposal转化到同一尺寸,从而实现卷积层特征共享。
- 采用 4-Step Alternating Training 和multi-task loss进行训练。
论文和代码的细节不在这里多费笔墨,可以参考一文读懂Faster RCNN -白裳和从编程实现角度学习Faster R-CNN(附极简实现)-陈云,他们的解析对我的理解帮助很大。
YOLO系列
YOLO-v1
YOLO全称You Only Look Once: Unified, Real-Time Object Detection,它是一种one-stage、end to end的检测方法,它与Faster RCNN的区别可以见下图:

简单来说,YOLO将整个检测问题整合为一个回归问题,使得网络结构简单,检测速度大大加快;由于网络没有分支,所以训练也只需要一次即可完成。这种“把检测转化为回归问题”的思路非常有效,之后的很多检测算法(包括SSD)都借鉴了此思路。

如上图所示,YOLO的检测流程简单概述如下:
- 将原图划分为S*S的网格。如果一个目标的中心落入某个格子,这个格子就负责检测该目标;
- 每个网格要预测B个bounding boxes,以及C个类别概率$Pr(class|object)$;
- 每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。这个confidence代表了所预测的box中含有目标的置信度和这个bounding box预测的类别准确率两重信息;
- 由于输入图像被分为SS网格,每个网格包括5个预测量:$(x, y, w, h, confidence)$和一个C类,所以网络输出是$SS(5B+C)$大小;
- 在检测目标的时候,每个网格预测的类别条件概率和bounding box预测的confidence信息相乘,就得到每个bounding box的class-specific confidence score。
- 使用NMS过滤得到最终的检测框体。
YOLO的网络结构如下图,采用卷积网络来提取特征,然后使用全连接层来得到预测值。网络结构参考GoogLeNet模型,包含24个卷积层和2个全连接层。对于卷积层,主要使用1x1卷积来做channel reduction(通道融合降维),然后紧跟3x3卷积。对于卷积层和全连接层,采用Leaky ReLU激活函数:$max(x, 0.1x)$,最后一层却采用线性激活函数。

YOLO有如下特点:
- 快。YOLO将物体检测作为回归问题进行求解,整个检测网络pipeline简单,可以端到端一次完成训练。
- 背景误检率低。YOLO在训练和推理过程中能“看到”整张图像的整体信息,而基于region proposal的物体检测方法在检测过程中,只“看到”候选框内的局部图像信息。因此,若当图像背景(非物体)中的部分数据被包含在候选框中送入检测网络进行检测时,容易被误检测成物体。
- 识别物体位置精准性差。
- 召回率低,尤其是对小目标。
YOLO-v2,v3
针对YOLO-v1中存在的问题,作者在v2中进行了改进,并在v3中进行了更多尝试。
YOLO-v2中的改进有以下几点:
- Batch Normalization
- High Resolution Classifier
- Convolutional With Anchor Boxes
- Dimension Clusters
- New Network: Darknet-19
- Fine-Grained Features
- Multi-Scale Training
此外,作者还同时提出了YOLO9000。
YOLO-v3中的改进有以下几点:
- Resnet
- FPN
SSD
SSD(Single Shot MultiBox Detector)是one-stage检测框架的一种,在准确度和速度上比同一时期同为one-stage的Yolo和two-stage的Faster R-CNN要好很多。SSD的网络结构图如下图所示:
下图显示了不同算法的基本框架图,对于Faster R-CNN,其先通过CNN得到候选框,然后再进行分类与回归,而Yolo与SSD可以一步到位完成检测。相比Faster R-CNN,SSD提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体;SSD中同样采用了不同尺度和长宽比的先验框(Prior boxes, Default boxes,在Faster R-CNN中叫做锚,Anchors);相比Yolo,SSD采用卷积来直接进行检测,而不是像Yolo那样在全连接层之后做检测。
SSD的几个特点详细描述如下:
- 网络结构
SSD中的特征提取主干网络使用的是VGG16,去除全连接层fc8,将fc6 和 fc7层转换为卷积层,pool5不进行分辨率减小。在fc6上使用dilated convolution弥补损失的感受野;并且增加了一些分辨率递减的卷积层(conv7-conv11),得到不同尺度的特征图。 - 设置先验框
在Yolo中,每个单元预测多个边界框,但是其都是相对这个单元本身(正方块),但是真实目标的形状是多变的,Yolo需要在训练过程中自适应目标的形状。SSD中使用位置和大小固定的Prior Boxes,即事先设置好的固定的proposal,相当于借鉴了Faster R-CNN中的Anchors概念,并有着自己的一套先验框匹配原则,具体可以参照原文和源码。 - 采用多尺度特征图用于检测
SSD使用不同深度的卷积层预测不同大小的目标,对于小目标使用分辨率较大的较低层,即在低层特征图上设置较小的Prior Boxes,高层的特征图上设置较大的Prior Boxes。 - 回归预测
SSD中使用3x3的卷积对每个Prior Box的类别和位置直接进行回归。
论文和代码的细节同样可以参考SSD 系列论文总结-方良骥与目标检测|SSD原理与实现-我是小将。
Backbone网络的改进
一些参考资料:
从LeNet-5到DenseNet -山隹木又
一文简述ResNet及其多种变体 -机器之心
为什么ResNet和DenseNet可以这么深?一文详解残差块为何有助于解决梯度弥散问题。 -justin ho
Resnet
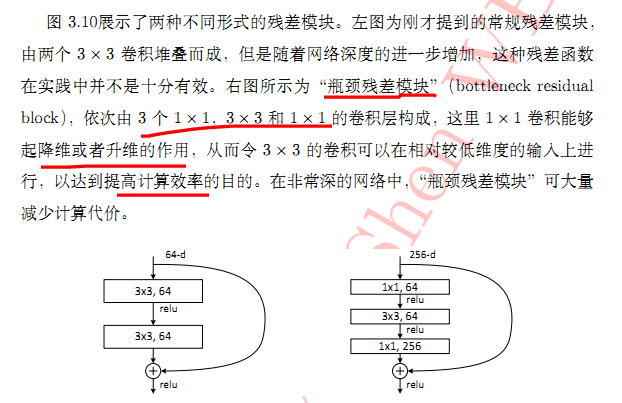
ResNet 主要的创新在残差网络,其实这个网络的提出本质上还是要解决层次比较深的时候无法训练的问题。这种借鉴了Highway Network思想的网络相当于旁边专门开个Short Cut使得输入可以直达输出,而优化的目标由原来的拟合输出H(x)变成输出和输入的差H(x)-x,其中H(X)是某一层原始的的期望映射输出,x是输入。
优化后的结构新结构中的中间3x3的卷积层首先在一个降维1x1卷积层下减少了计算,然后在另一个1x1的卷积层下做了还原,既保持了精度又减少了计算量。
Densenet
借用论文里的话,ResNet直接通过”Summation”操作将特征加起来,一定程度上阻碍(impede)了网络中的信息流。DenseNet通过连接(concatenate)操作来结合feature map,并且每一层都与其他层有关系,都有”沟通“,这种方式使得信息流最大化。其实DenseNet中的dense connectivity就是一种升级版的shortcut connection,提升了网络的鲁棒性并且加快了学习速度。