本篇笔记包括对目标检测中的一些提升的方法技巧的介绍,包括:
- Data Augmentation
- OHEM
- Deformable Conv
- Focal Loss
- SoftNMS
不断更新ing…
本篇笔记包括对目标检测中的一些提升的方法技巧的介绍,包括:
不断更新ing…
论文名称:《Feature Pyramid Networks for Object Detection》
论文链接:https://arxiv.org/abs/1612.03144
参考代码(非官方):https://github.com/jwyang/fpn.pytorch(Pytorch实现)
多尺度目标检测是计算机视觉领域的一个基础且具挑战性的课题,尤其是在目标检测方面。下图是目前常用的四种多尺度处理方法。
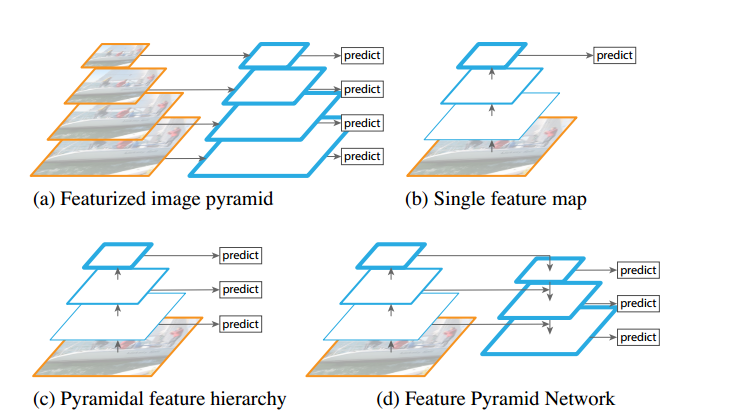
依次介绍一下这四张图的多尺度处理方法。
论文名称:《Towards End-to-End Lane Detection an Instance Segmentation Approach》
论文链接:https://arxiv.org/abs/1802.05591
参考代码(非官方):https://github.com/MaybeShewill-CV/lanenet-lane-detection
传统车道线检测方法主要依赖于高度专门化,手工提取特征和启发式方法来分割车道线。在传统方法中,较为常见的手工特征有基于颜色的特征、结构传感器特征、Ridge特征等,结合Hough变换或卡尔曼滤波等方法实现车道线识别。识别出车道线之后,利用后期图像处理技术过滤掉误检等情况得到最终车道线。
近些年来,更为流行的方法是用深度网络提取深度特征代替手工特征,实现如像素级别的车道线分割。目前流行的深度学习车道线检测方法可以很好地分割出车道线像素,其较为大的感受野可以在标注模糊或无标注的情况下估计出大致车道线。
然而这些方法产生的二值化车道线分割图仍需要分离得到不同的车道实例。为处理这个问题,一些方法采用后处理来解决,主要是用启发式的方法,比如几何特性。但启发式方法计算量大且受限于场景变化鲁棒性问题。另一条思路是将车道检测问题转为多类别分割问题,每条车道属于一类,这样能实现端到端训练出分类好的二值图像。但该方法受限于只能检测预先定义好的固定数量的车道线,无法处理车道的变化。
基于此,作者提出了LaneNet模型,不仅能够得到车道线像素,还能将不同的车道线实例区分开。
得到车道线实例后,需要对每条车道线进行描述。最常用的描述方法是曲线拟合车道线模型,目前流行的曲线拟合模型有三次多项式,样条曲线,回旋曲线等。为了提高拟合质量且保持计算效率,通常我们将图像转到鸟瞰图后做拟合。最后再逆变换到原图即可。然而,目前所使用的透视变换矩阵的参数通常是预先设定、不会改变的,在面对外部地形影响(如上坡)等情况下的车道线拟合并不准确,鲁棒性不强。
基于此,作者提出了H-Net模型,用来用来学习透视变换矩阵的参数。
这便是这篇论文的两个创新之处,接下来将详细展开分析。
论文名称:《Focal Loss for Dense Object Detection》
论文链接:https://arxiv.org/abs/1708.02002
参考代码:Detectron,https://github.com/fizyr/keras-retinanet(Keras实现)
在深度学习之前,经典的物体检测方法为滑动窗口+人工设计的特征。而目前主流的检测算法可以分为两类:one-state和two-stage。前者以YOLO和SSD为代表,后者以RCNN系列为代表。
R-CNN系的方法是目前最为流行的物体检测方法之一,同时也是目前精度最高的方法。在R-CNN系方法中,正负类别不平衡这个问题通过处理第一阶段产生的候选区域解决了。使用EdgeBoxes,Selective Search,DeepMask,RPN等处理方法,可以过滤掉大多数的背景,将比较少的、包含物体的候选区域(1-2K)传到下一个阶段。
但在YOLO,SSD等方法中,由于对计算速度提升的要求,需要直接对特征图的产生的大量候选区域(100K)进行检测,而且这些区域很多都在特征图上重叠,是为简单的负样本。大量的这些简单负样本造成了样本不均衡,会给训练带来以下两个问题:
常见的处理这些负样本的方法之一是SSD中用到的OHEM(online hard example mining)。OHEM通过对样本进行loss评估,再使用NMS舍弃了这些简单无用的负样本,但同时也丢失了其中许多可以利用的信息。
作者明确指出,one-stage检测器之所以在精度上不如two-stage检测器,核心问题(central issus)是大量的负样本造成的样本不均衡。因此,作者提出了Focal Loss,希望使one-stage检测器在不影响原有速度的情况下,达到two-stage检测器的准确率。
Focal Loss是是在标准交叉熵损失基础上修改得到的一种新的损失函数。这个函数可以通过减少易分类样本的loss权重,使得模型在训练时更专注于难分类的样本。
为了证明Focal Loss的有效性,作者还设计了一个one-stage的检测器:RetinaNet,在训练时采用Focal Loss。实验证明RetinaNet不仅可以达到one-stage 检测器的速度,也能达到two-stage检测器的准确率。

这次比赛是我第一次完完整整参加下来的比赛。一开始的时候,自己遇到了挺多的困难,不过很幸运结识了很棒的队友们,一起努力和提高,并在北京一起参加了决赛。虽然最终很遗憾和前三擦肩而过,不过还是收获很大。决赛的队伍都有很好的思路和方法,答辩的时候学习到了很多。
本文旨在分享一下我们队的解决方法以供参考,并且总结记录一下别人的良好思路。代码稍微整理了一下,放在了github上抛砖引玉,有需要的可以自取~
Multi-Agent Particle Environment(MPE)是由OpenAI开源的一款多智能体强化学习实验平台,以OpenAI的gym为基础,使用Python编写而成。它创造了一个简单的多智能体粒子世界,粒子们可以进行连续的观察和离散的动作。
